模版图
简介
算法图主要可以分为以下3类:
| 类别 | 描述 | 使用场景 | 优点 | 缺点 |
|---|---|---|---|---|
利用深度学习目标检测、实例分割方法或2D图像形状匹配方法进行图像分割,再结合点云信息进行后处理得到结果。 |
袋子,箱子等目标表面纹理特征明显,易于区分的场景,或目标形变无法用点云匹配的场景。 |
能够应对非刚体;针对点云效果不好的情况可能有一定优势。 |
需要采集图像进行标注训练。 |
|
直接用目标匹配 |
适用于表面不平整或难以提取目标边缘的的刚体场景,如曲轴,角阀等表面不平整的零件等。 |
能够应对复杂姿态下的物体。 |
精度依赖于点云的质量。 |
|
用目标提取边缘做匹配 |
适用于目标表面平整且边缘明显的刚体场景,如耐火砖场景。 |
相比较直接点云匹配速度更快。 |
精度依赖点云质量;依赖目标的边缘。 |
|
多视角方法进行匹配 |
适用于遮挡情况较多的场景。 |
对遮挡场景效果较好;需要调参少;可根据工件设置视角。 |
速度受尺度影响较大。 |
|
用2D方法先将目标附近区域提取出来再进行匹配。 |
针对一些没有形变但是可能目标间缝隙太小难以很好匹配的场景。 |
能够应对物体间缝隙小造成的匹配困难。 |
需要图像和点云的操作,总体耗时可能较高。 |
模板图
模板匹配
-
下载:单击此处下载图文件
-
说明:
深度学习
|
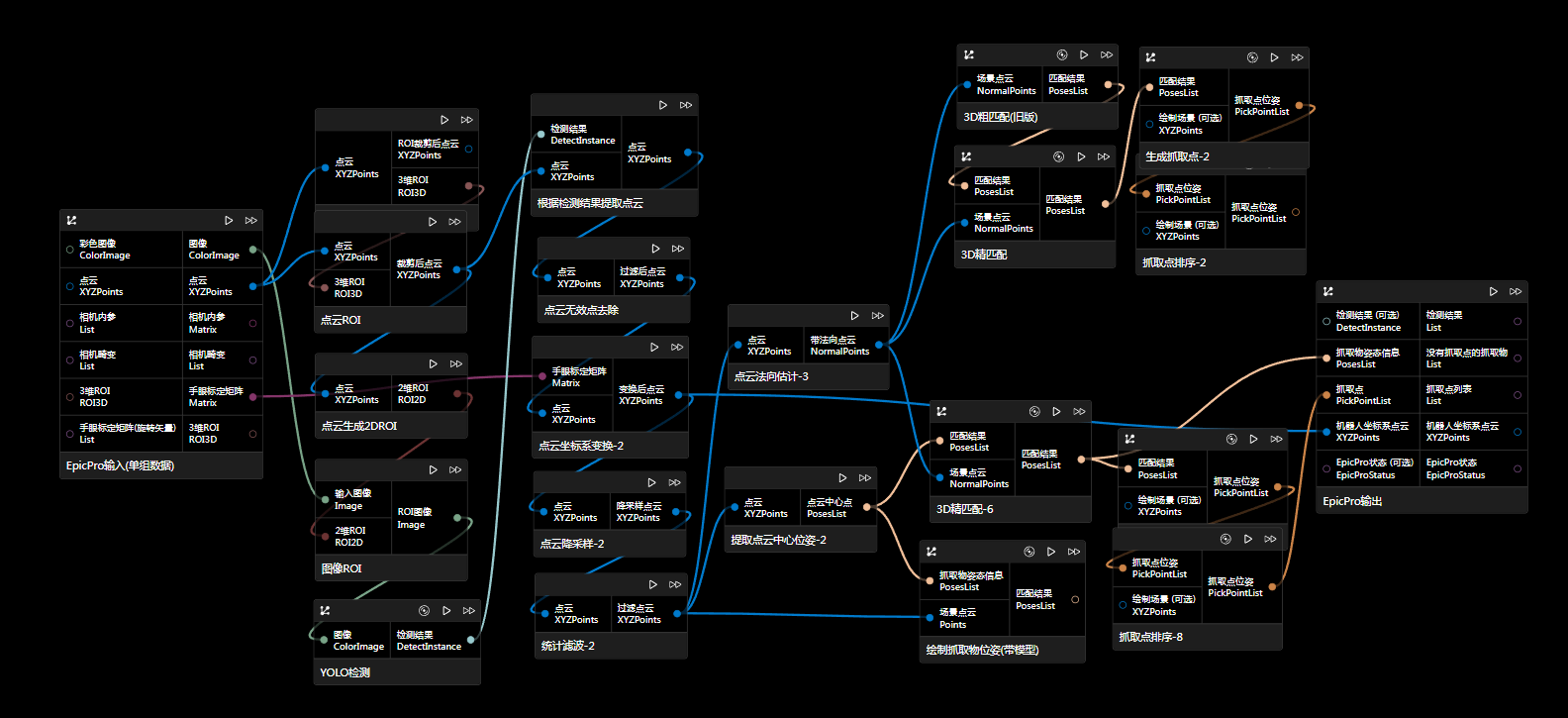
方案一(推荐)
-
说明:
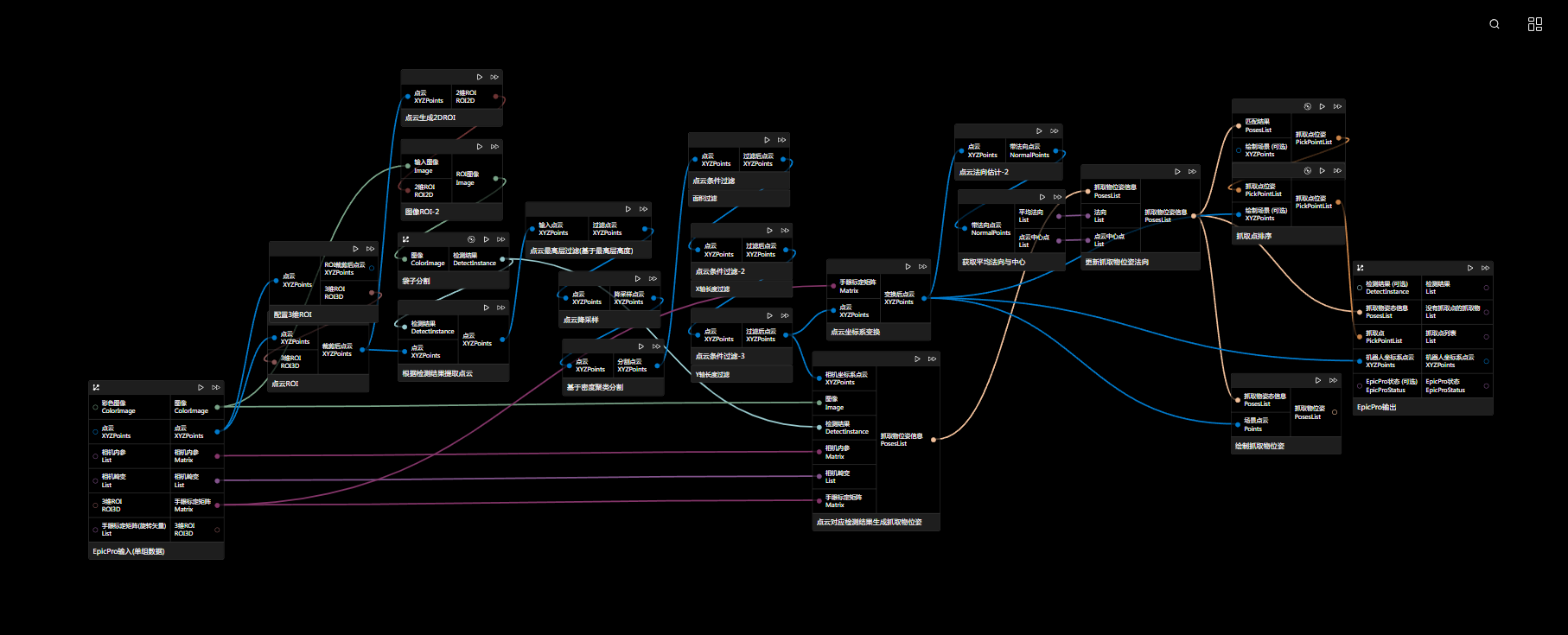
该方案是先进行图像检测,再对点云做处理,对点云的过滤等各种处理都可以使用,最后用接近实际目标的多块点云输入到点云对应检测结果生成抓取物位姿节点生成poseList,再进行法向更新,最后生成抓取点并过滤。
该方案中,更新位姿法向使用的是“机器人坐标系下的点云”计算出来的法向等结果,其他两个方案也同样需要用机器人坐标系下点云进行计算。
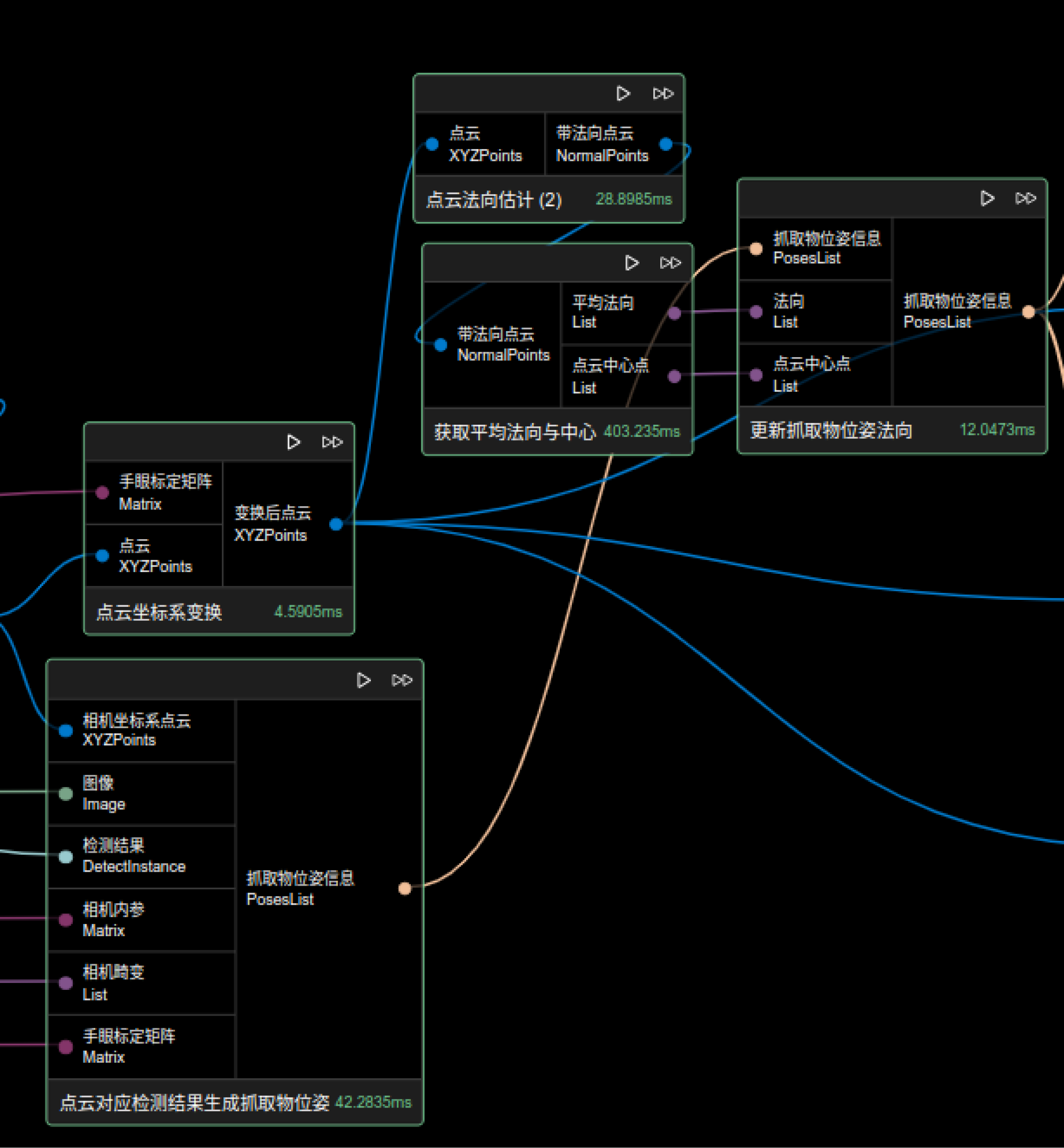
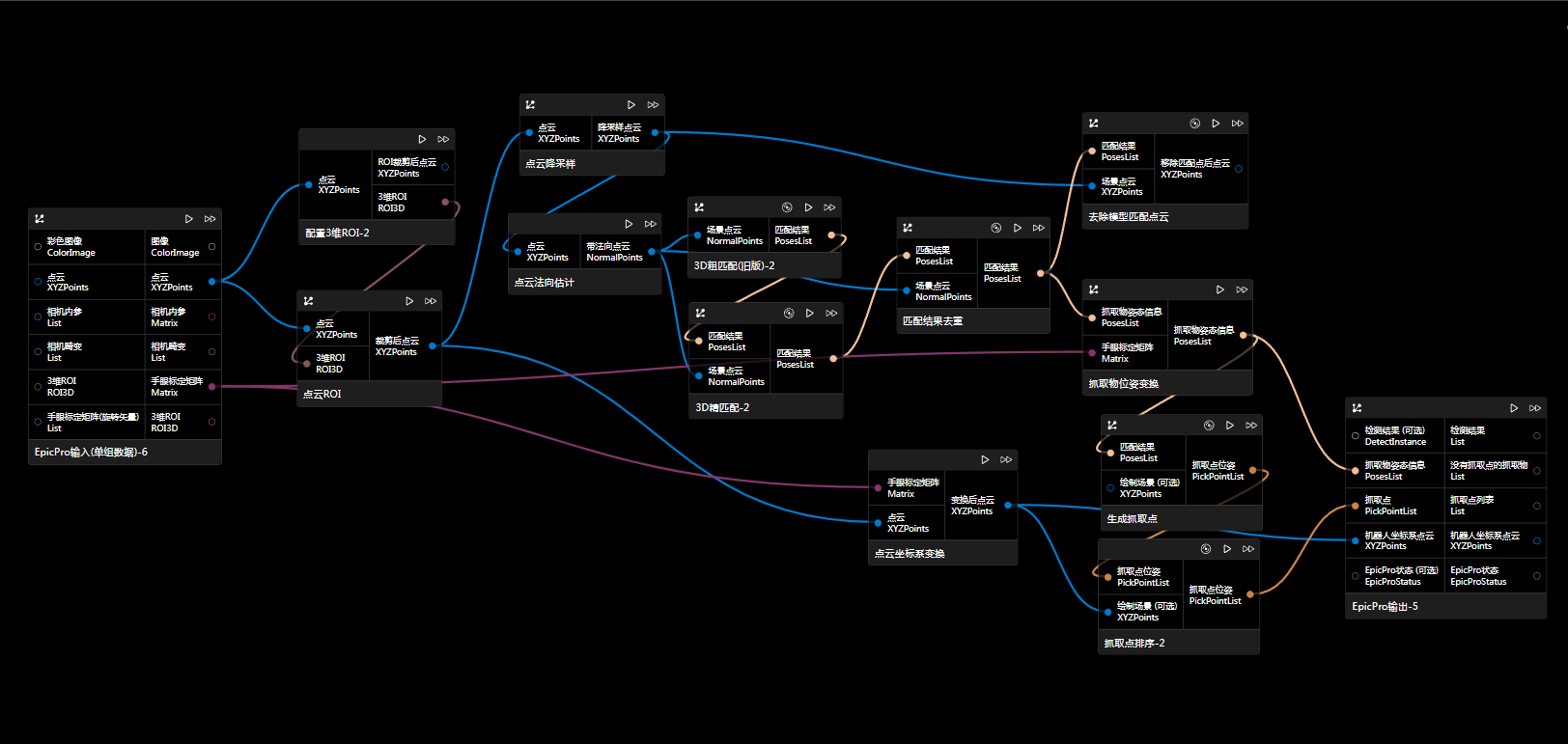
方案二
-
下载:单击此处下载图文件 、单击此处下载相关数据
-
说明:
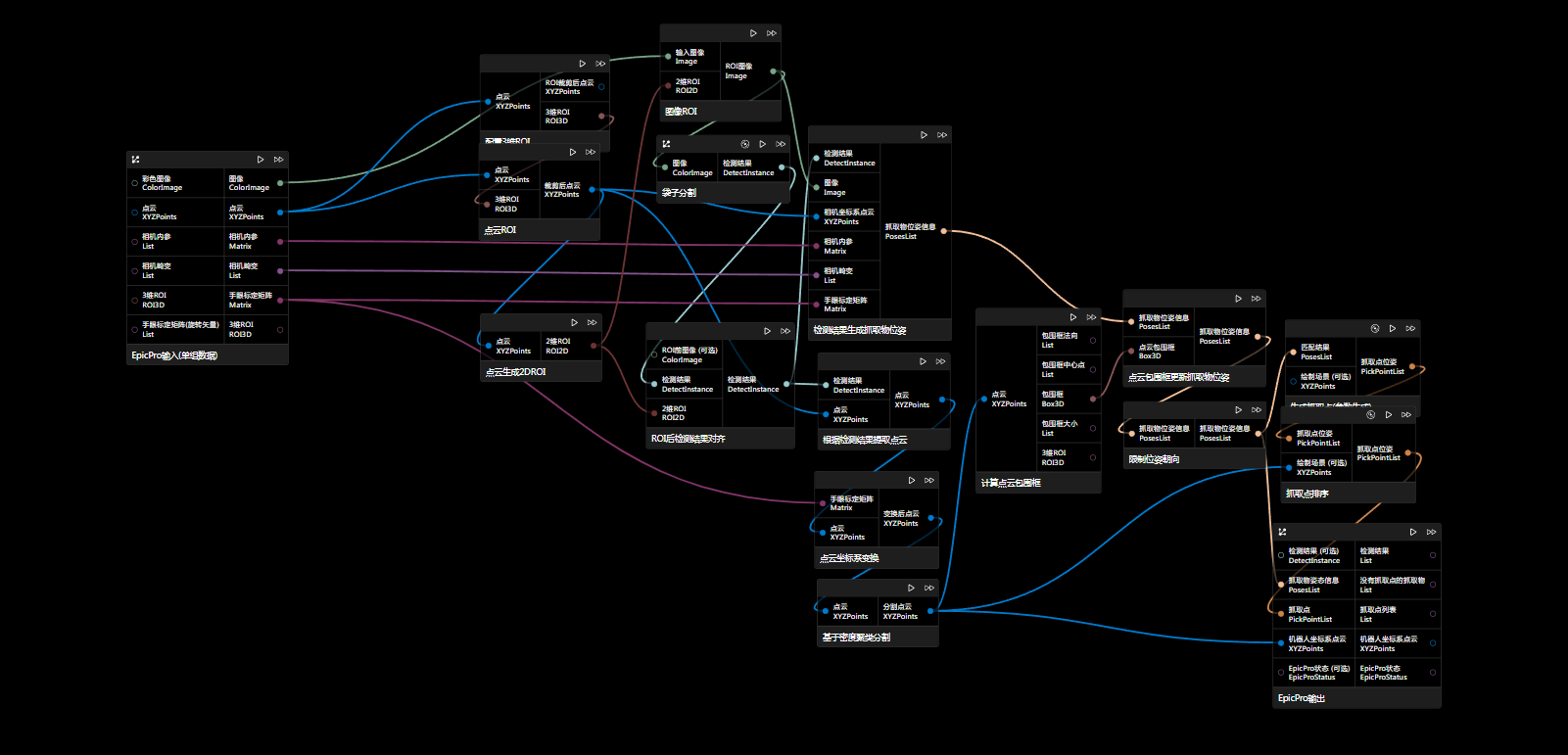
直接将检测结果对应输入点云得到抓取物位姿,再进行法向或旋转更新。
该方案中先编辑点云ROI(这里的ROI需要打开保持有序和保持原大小的开关)然后利用设置ROI后的点云生成2D ROI进行图像ROI,再用“ROI后检测结果对齐”节点,将检测结果对齐到原图大小,这样才能对齐回原点云进行点云数据的提取。
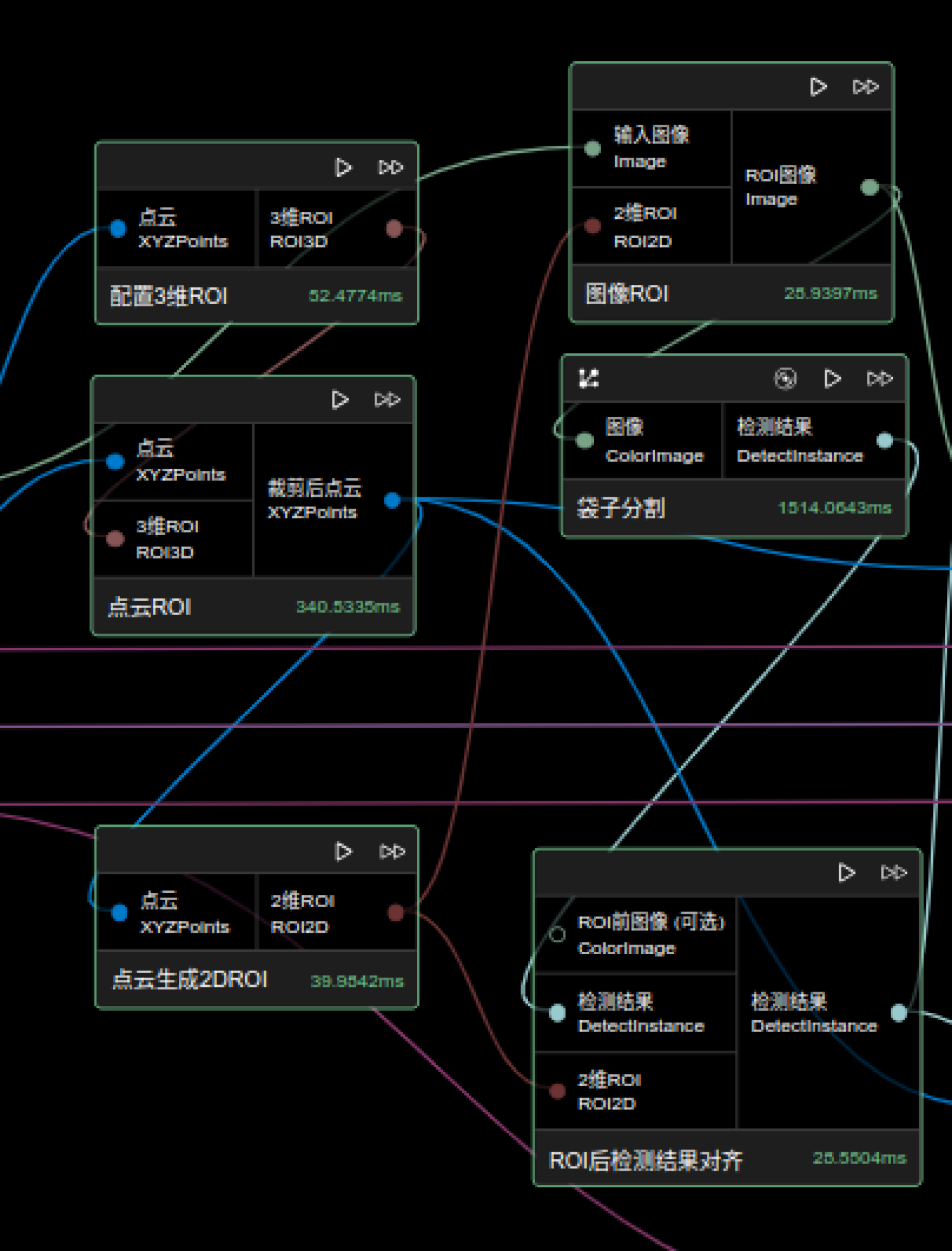
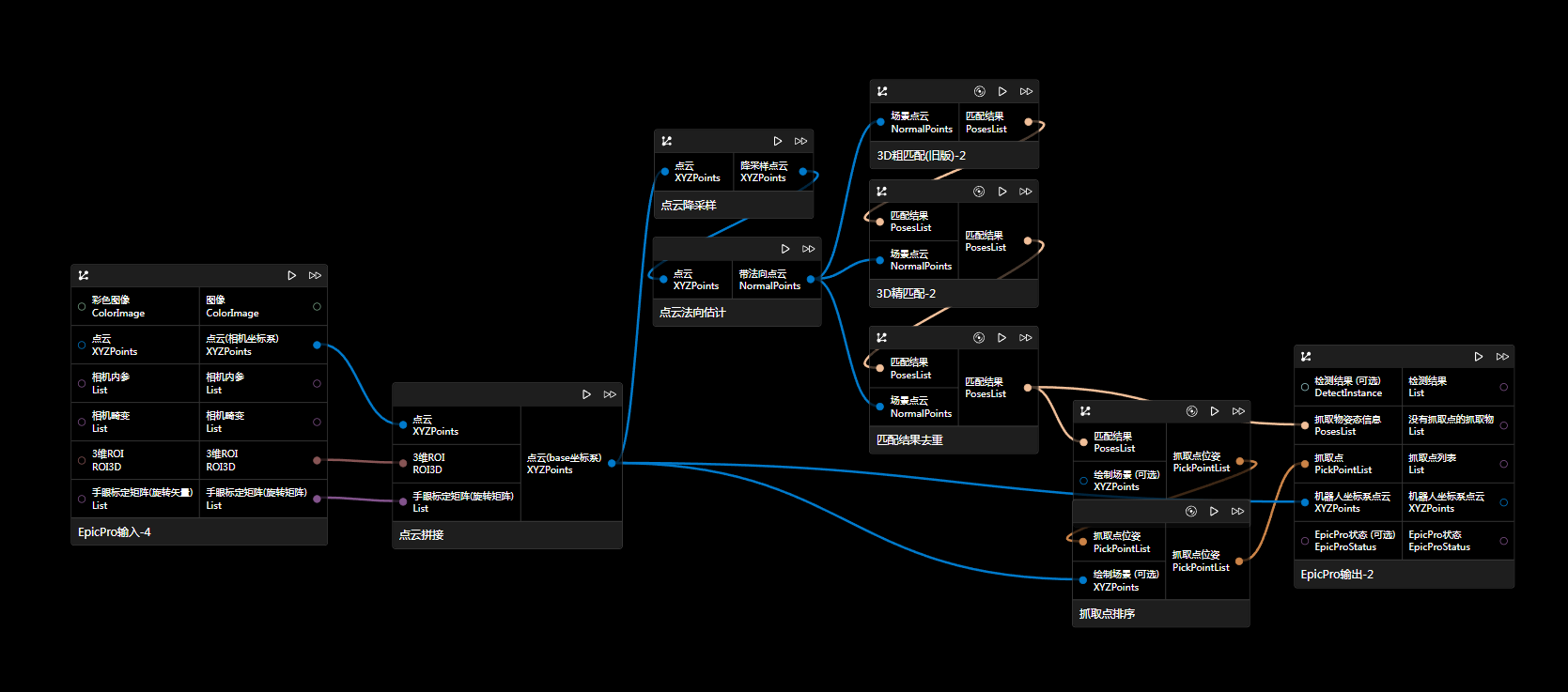
方案三
-
下载:单击此处下载图文件
-
说明:
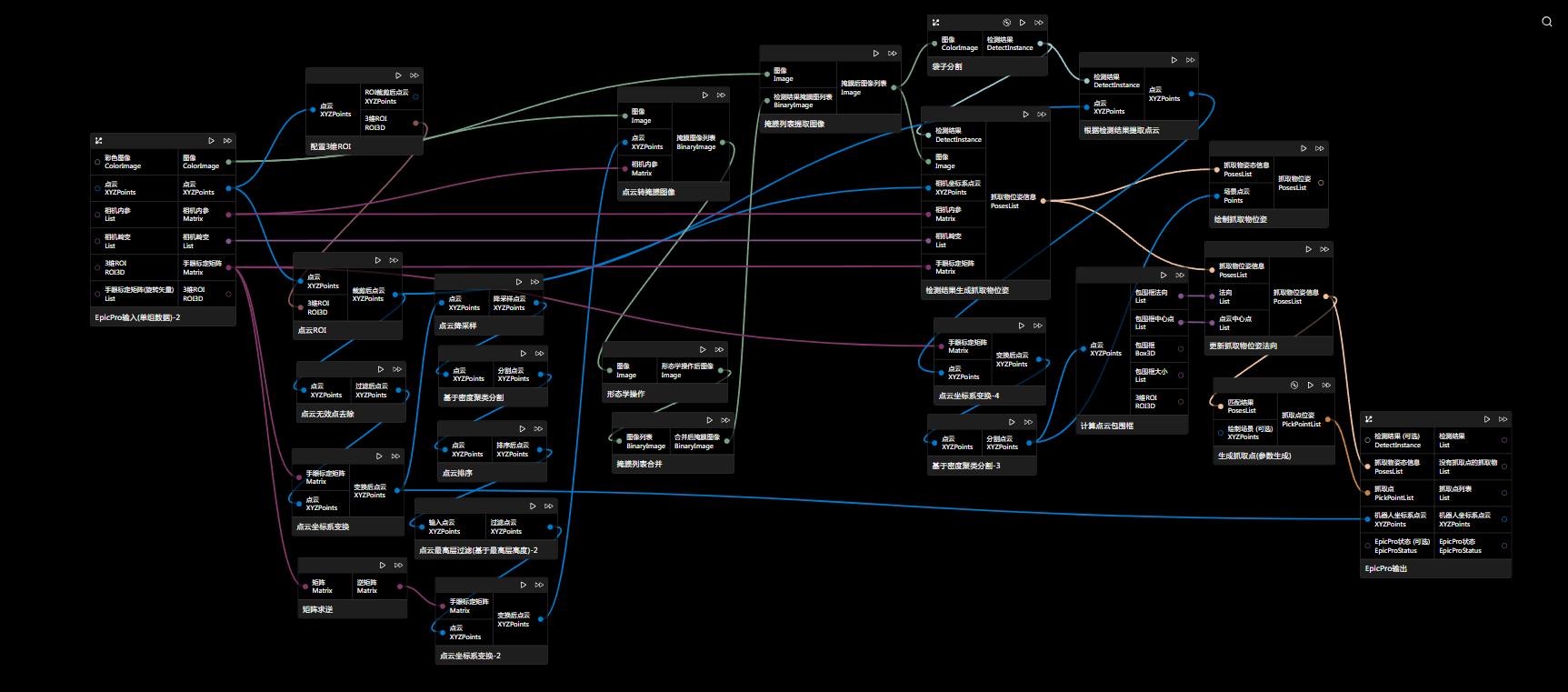
通过点云处理,将点云对应图像提取出来,再进行图像分割或检测。
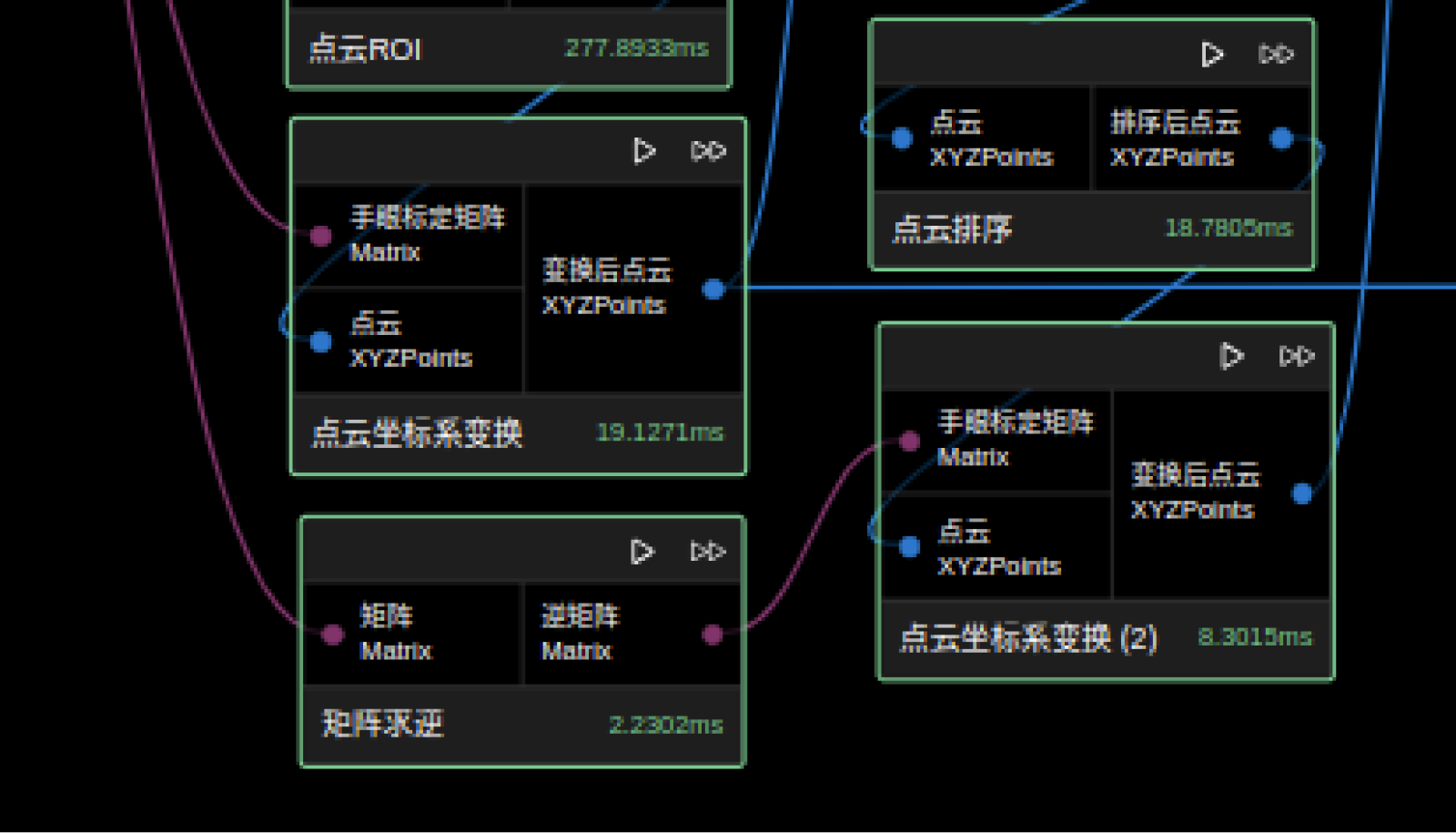
由于相机坐标系下的点云相较于机器人坐标系下的点云在高度等排序上可能会有偏差。因此,该图中进了两次点云坐标系变换,第一次是将点云转换到机器人坐标系下,以提高排序的准确性;由于生成抓取物位姿节点时需要利用内参数据进行计算,而这些计算需要相机坐标系下的点云,所以进行了第二次变换,具体操作是通过手眼标定矩阵的逆矩阵,将机器人坐标系下的点云再转换回相机坐标系下。若相机坐标系下点云适合做点云排序等操作,也可以省略此步骤。
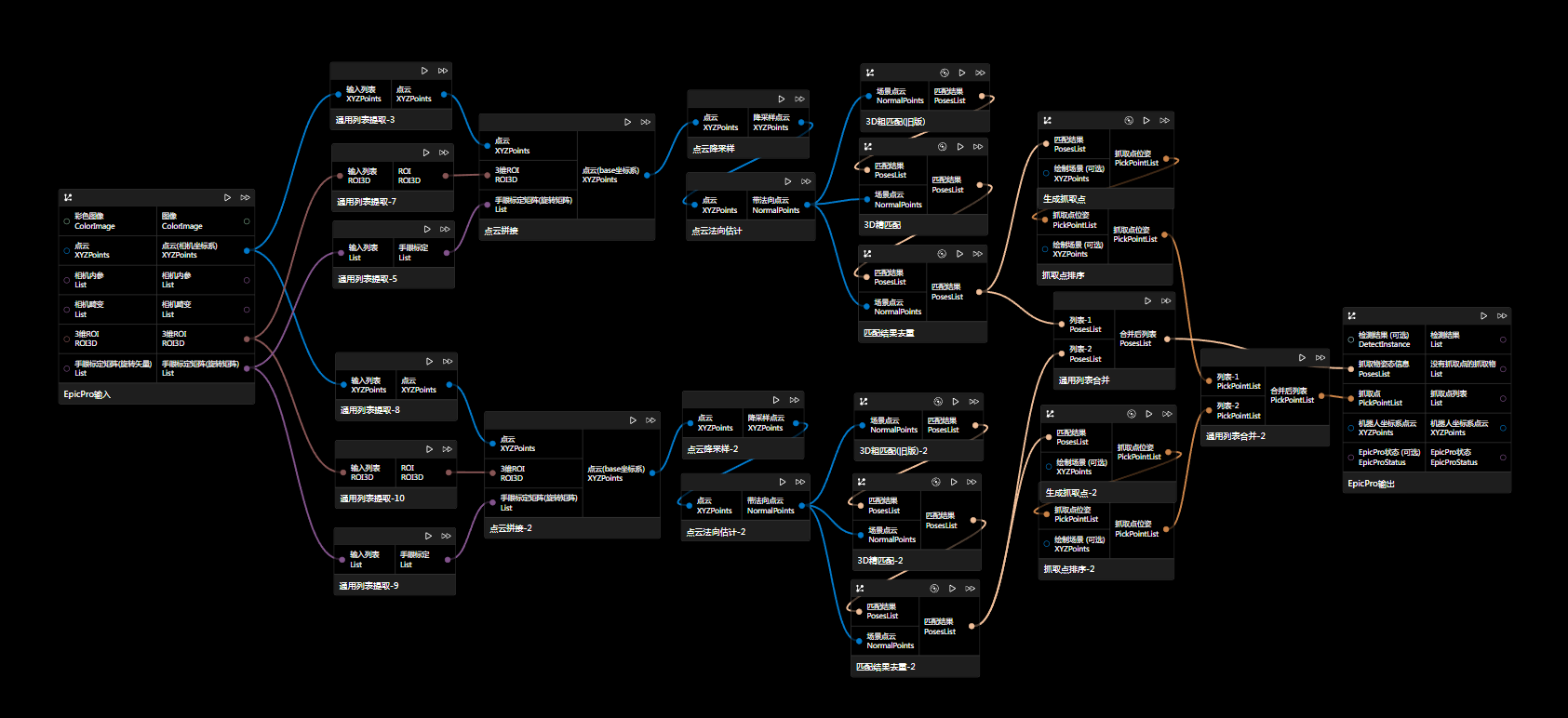
深度学习 + 模板匹配
-
下载:单击此处下载图文件
-
说明:
先进行深度学习,后进行匹配或精匹配来更精确的获取结果位姿。下图中绿色框和红色框里面是深度学习处理后的两种匹配方案,可根据场景选其一。