大模型(探索性)
主要流程概述
该流程可以被简单表述为以下步骤:
-
输入点云和图像信息
-
对点云或图像进行预处理, 分以下两种情况:
-
对点云信息进行预处理, 进行ROI、过滤、筛选、滤波、聚类生成等操作
-
对图像信息进行预处理, 进行ROI等操作
-
-
对点云或图像处理, 得到2维检测框和中心点以及掩膜, 分以下两种情况:
-
基于图像识别方法(如YOLO检测或GroundingDino)获取物体的边界框等二维识别信息, 进而通过检测结果获取2维检测框+中心点+掩膜
-
基于点云获取包围框转换成2维检测框+中心点+掩膜, 或基于点云直接获取图像掩膜, 进而获取检测结果进行拆分得到2维检测框+中心点+掩膜
-
-
将得到的2维检测框+中心点输入到SAM节点进行分割
-
进行后处理, 基于匹配点云生成位姿, 抓取点
流程设计参考
(1) 设计思路
针对此流程, 有两种思路:
-
可以使用2D图像检测识别, 再连接SAM分割节点, 如下
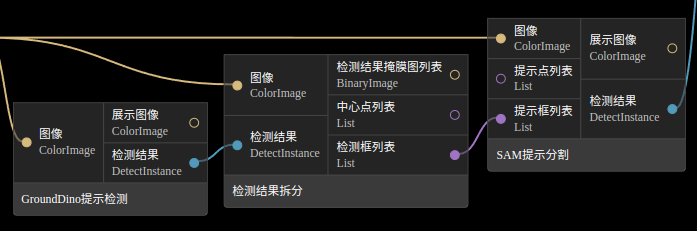
-
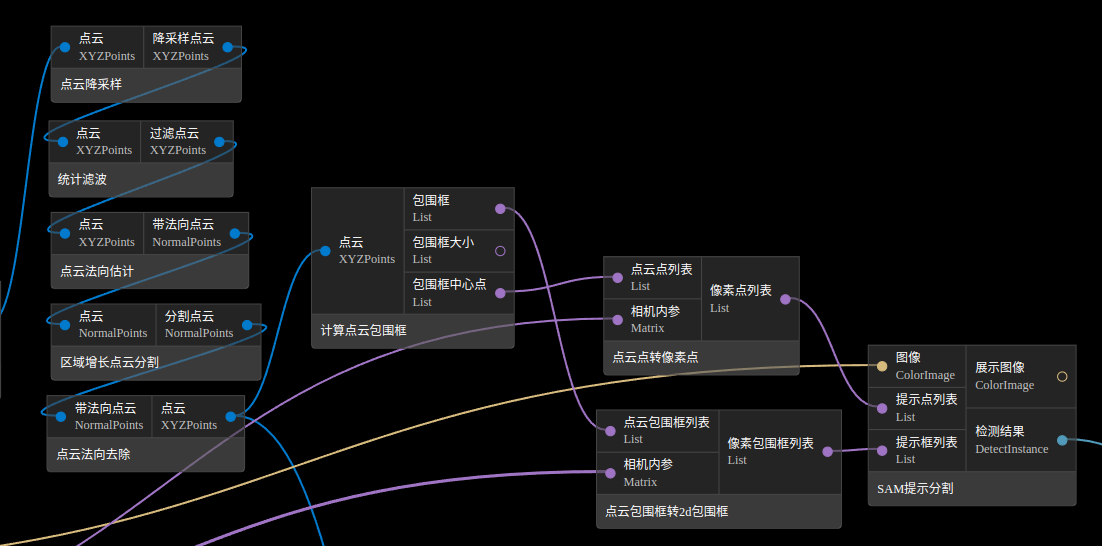
可以使用点云分割等提取2d包围框, 再连接SAM分割节点, 这一思路有两种实现方案, 如下图:
第一种是对点云分割结果进行包围框的计算, 转换到像素坐标系得到2维包围框和中心点作为SAM分割节点的提示输入
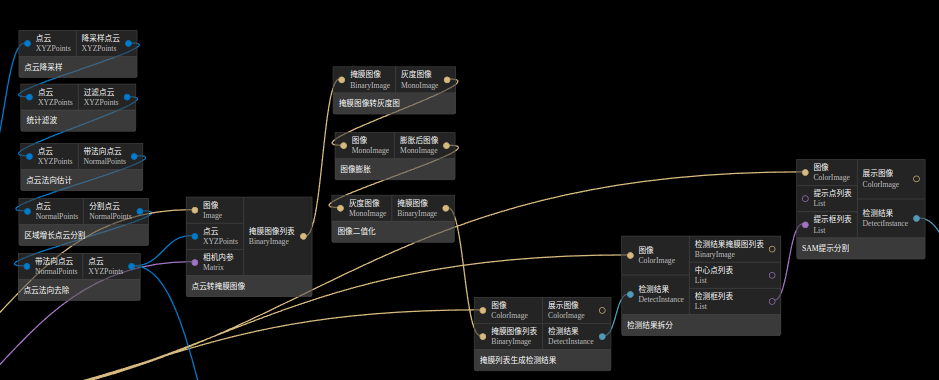
第二种是通过点云分割等方法拿到掩膜, 对掩膜进行一些图像操作, 再生成检测结果, 对检测结果进行拆分得到SAM提示分割的输入
(3) 点云或图像获取2维检测框和中心点
对图像操作, 可通过图像检测或2d形状匹配得到粗略的检测框, 输入到SAM中进行分割
对点云的操作主要是先进行分割(可根据情况使用不同分割方法), 得到单块的点云, 然后通过不同方法得到2维检测框和中心点:
用计算点云包围框节点获取点云包围框, 再通过点云点转像素点和点云包围框转2d包围框节点将3维结果转换到2维
用点云转掩膜图像节点将3维结果转换到2维, 拿到基础的掩膜, 但此时的掩膜由于点云降采样及点云的缺失等问题可能会不连续或不完整, 需要通过图像膨胀、图像二值化等操作进行掩膜处理, 以得到更好的结果, 再通过掩膜生成检测结果节点和检测结果拆分节点得到2维检测框和中心点,
(4) SAM分割
将前面获得的2维检测框或中心点输入到SAM分割节点, 这里一般推荐将检测框作为提示输入就足够, 也可将中心点和检测框一起输入, 一般单独用中心点作为提示的结果效果不够好。
在atom1.1.2版本, 集成了FastSam节点, 其功能与SAM一致, 但时间消耗更少, 效果并未进行具体的比较, 可根据实际情况选用。
(5) 结果后处理
参见前文纯图像识别流程或纯点云匹配流程中后处理流程设计, 纯图像识别后处理流程
-
参数调优
此流程参数调优可参考以上几个流程的参数调优, 在此只对几个特殊节点进行说明, 其他不多赘述
1. GroundDino节点
-
原理:
-
使用GroundDINO模型用语言提示进行图片检测
-
-
参数:
-
权重文件: 模型文件, 模型需要与模型类型中对应选择SwinB和SwinT_OGC, 下载路径 groundingdino_swint_ogc.pth 和 groundingdino_swinb_cogcoor.pth
-
模型类型: SwinT_OGC, SwinB两种对应groundingdino的两种模型, 具体不做解释, 有兴趣可自行去github查看, 一般默认SwinT_OGC
-
开启GPU: 设置是否使用GPU做推理, 若开启需要电脑具有显卡环境
-
提示词句: 给定英文提示词或句子, 根据词句对图像进行检测, 找到对应检测框, 若有多个类别目标, 可用英文符号.或, 分隔开词语
-
类别映射: 根据设置的给定英文提示词或句子, 设定类别为0、1、2、3等大于等于0的值, 用于后续对结果根据类别的过滤, 多个类别可用英文符号.或, 分隔开, 且类别数量需大于等于提示词句数量, 若不一致或不设置, 则按默认的0、1、2、3、4
-
检测框置信阈值: 检测框阈值, 越高结果越少
-
检测类别置信阈值: 检测类别阈值, 越高结果越少
-
注意点:
本模型依赖groundingdino这一python库, 若没装则需要在qianyi的pypi源中用pip install groundingdino安装, 由于运行需要下载一些数据, 且网站有限制, 可能会报错, 若运行时报错’We couldn’t connect to 'https://huggingface.co' to load this file, couldn’t find it in the cached files and it looks like bert-base-uncased is not the path to a directory containing a file named config.json' 则可下载相应文件并解压到路径(若已存在该文件夹, 则替换掉即可) /home/XXX/.cache/huggingface/hub下。下载链接为 models—bert-base-uncased。
1. SAM节点
-
原理:
-
使用Segment Anything模型, 输入boxes或points提示进行图片的分割
-
本模型依赖segment-anything这一python库, 若没装则需要在qianyi的pypi源中用pip install segment-anything安装
-
-
参数:
-
权重文件: 模型文件, 模型需要与模型类型相对应, 官方模型下载路径为 sam_vit_b_01ec64.pth、 sam_vit_l_0b3195.pth、 sam_vit_h_4b8939.pth
-
模型类型: vit_b、vit_l、vit_h分别对应SAM的小模型, 中模型, 大模型
-
开启GPU: 设置是否使用GPU做推理, 若开启需要电脑具有显卡环境
-
置信阈值: 分割阈值, 越大结果越少
-
输出多个结果: 对每一个提示, 是否输出多个结果, 若为True则每个提示输出3个掩膜, 若为False则只输出一个
-
是否缩放: 是否对输入图像先做缩放后做分割, 是为了将图像做缩放, 以减少SAM的运行速度
-
缩放范围: 图像缩放大小, 默认为1表示不缩放, 缩小图像大小和输入提示数据可减少资源消耗, 但分割精度可能会下降, 只在是否缩放为True时有效
-
按输入图尺寸输出结果: 是否按输入图尺寸输出结果, True为按输入图像尺寸输出结果, 只在是否缩放为True时有效
-
类别名: 可根据场景设置类别名称, 以进行过滤等操作
-
3. FastSam节点
-
原理:
-
使用FastSam模型, 输入boxes或point、文字提示进行图片的分割, 若选择的分割类型对应的输入提示为空, 则使用自动分割
-
本模型依赖fastsam这一python库, 若没装则需要在qianyi的pypi源中用pip install fastsam安装, 安装时会同时安装clip和ultralytics两个库, 若运行显示没有此节点, 可往这个方向查找问题
-
-
参数: 初始化参数:
-
权重文件: 模型文件, 官方模型下载路径为 FastSAM-x.pt、 FastSAM-s.pt
-
开启GPU: 设置是否使用GPU做推理, 若开启需要电脑具有显卡环境, 本节点为了让其在1650显卡上运行GPU版本, 在后处理部分使用了CPU运行, 以防止显存溢出。所以打开GPU的情况下, 如果置信阈值较小, 检测结果过多, 进行后处理的时间会变长。
-
图像尺寸: 在运行分割时将图像缩放到的尺寸, 默认640,也可用1024、512、256等2的幂次, 这个尺寸会影响运行时间和精度, 一般而言尺寸越小越快
-
置信阈值: 分割阈值, 此值越大分割出来结果越少后处理时间会更少, 越小则分割出来结果越多, 后处理时间会增加
-
IOU阈值: 结果的IOU阈值, IOU大于此值时过滤掉目标 运行时参数:
-
分割类型: 推荐box_prompt方法, 选择使用box提示、points提示、文字提示还是分割一切, 此参数的值需与输入的点、box、文字prompt对应, 否则会默认分割everything
-
类别名: 可根据场景设置类别名称, 以进行过滤等操作
-
面积阈值: 通过mask面积过滤掉部分结果
-
提示词: 可根据图片内容和待分割目标进行设置, 如: bag
-
文字提示阈值: 文字提示阈值, 将文字检测结果过滤掉一部分低于得分的值, 注意: 此阈值并非结果图中显示的阈值, 一般不能设置太高
-
3. 点云转掩膜图像
-
原理:
-
将点云点通过内参转换为2维图像上的点, 进而将这些点变成掩膜图像
-
-
参数:
-
是否取最小包围框: 设置是否取点云对区域的最小包围框为掩膜区域, 若为False, 则得到的掩膜图像有可能会是一堆不连续的像素点, 为True, 则得到的掩膜图像会是一些矩形图像, 可能会跟实际点云形状有差别
-
4. 掩膜列表生成检测结果
-
原理:
-
将掩膜列表变成Polygon, 生成检测结果
-
-
参数:
-
结果类别: 可通过此值指定生成的检测结果类别, 主要是用于后续类别过滤等操作
-
5. 计算点云包围框
-
原理:
-
用不同的方法对输入点云列表中每一个点云计算包围框, 要求输入的点云已经做过过滤, 避免飞点等对计算的影响, 以保证包围框计算准确
-
-
参数:
-
计算方法:
-
OBB最小包围盒: 此方法是通过计算点云的协方差矩阵, 得到特征向量作为点云的主方向, 进而得到一个旋转矩阵, 得到点云在此坐标系下的最小最大值, 最后转换到原点云坐标系下得到最小包围框
-
AABB坐标对齐包围盒: 此方法是在坐标轴方向上生成一个包围点云的最小框, 即计算这一片点云的最小值和最大值作为包围框的顶点。
-
-
6. 点云点转像素点、点云包围框转2D包围框
-
原理:
-
通过内参将点云点或点云包围框的角点转为像素上的点
-
-
参数:
-
无
-