纯图像识别流程
主要流程概述
纯图像识别的流程主要有以下几个步骤:
-
输入图像,点云信息 (这里的点云信息是为了后续过滤处理与生成抓取操作,并不会用于识别)
-
对输入信息进行预处理,比如 RoI 的选择
-
使用目标检测或实例分割对图像进行感知,也可以用形状模版进行匹配
-
进行结果后处理,基于感知结果,结合点云,进行过滤和位姿估计,生成最终的抓取目标
流程设计参考
(1) 预处理流程设计
预处理的目的是,优化输入的数据,使得后续操作更加快速,精确。
在纯图像识别流程中,较为常见的是RoI的选取,这里有两种可能的选取设计:
使用配置3维ROI节点进行手动选取,或通过EpicPro输入节点输入3维ROI,然后使用3维RoI转2维RoI算子,配合彩色图像RoI算子进行图像的预处理
直接进行二维的RoI选取,通过 配置2维RoI 算子进行实现
针对此类场景,由于需要点云和图像形状对齐,若要对点云和图像进行ROI,则需要选择保持形状的ROI,且其运行时参数尽量使用默认的nan值进行填充,如下图:
|
|
若输入为本地读取的点云和图像,当其形状不对齐时,可使用点云对齐图像形状来进行处理:
若使用的模型不是针对当前数据训练的,识别效果不好的话,可以通过图像特征的一些操作进行处理,如以下图中的一些节点:

(2) 目标检测模型,实例分割模型,形状模版匹配的选择
可选方法节点如下,下图中前面的六个节点对应的模型可在训练服务中下载,:
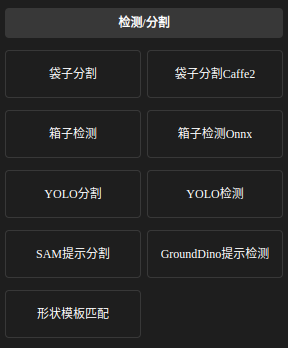
目前ATOM具有 YOLO检测以及分割的模型,这两个模型都能够进行目标检测,选取标准为:
当处理的物体是比较规则的长方体或者正方体时,可以使用YOLO检测
当处理的物体的投影是比较规则的矩形时,使用YOLO检测
对于比较复杂形状或者非刚体的物体,则需要使用实例分割模型
针对目标特征明显,受光照影响小,且不出现形变的情况,可使用2d形状模版匹配,针对此场景,预处理中的图像特征处理往往可以更好地提取特征,提高匹配效果
(3) 后处理流程设计
后处理的目的是,对结果进行优化,排除掉一些异常或者错误的结果,该流程可以被分为几个类别:
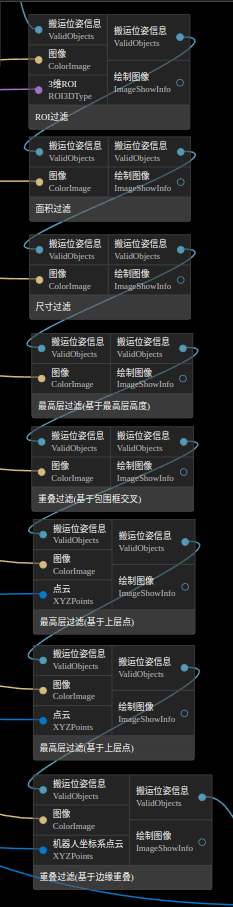
1. 结果过滤:RoI过滤,面积过滤,尺寸过滤,重叠过滤,最高层过滤
结果过滤的相关方法主要是针对搬运位姿数据进行处理,以下图中的过滤处理节点并不是一定要存在的,可根据场景打开或关闭使能开关。若某节点表现不好,或者在当前场景不需要,可直接关闭运行时参数中的使能开关,该节点将不做处理,直接将输入传递到输出,避免了节点之间连线的处理。
同时,搬运位姿的生成及后处理相关节点的图像输入是用于调试显示中间结果的,可不连接,但需要该节点的运行时参数中绘制图像开关关闭,否则会报错。
2. 结果生成:生成搬运位姿,格式转换,抓取点生成,抓取点排序
由于前面过程中得到的搬运位姿无法进行抓取点的处理和输出到EpicPro进行抓取,需要通过格式转换节点转换成PoseList进行后续操作。但转换后的抓取物姿态朝向均为朝上,往往无法抓取,需要通过生成抓取点(参数生成)和抓取点排序将抓取朝向改为机器人抓取的方向,具体的连接流程如下,具体调参可见结果生成参数调优部分。
生成抓取点(参数生成)节点在此处的作用主要是通过沿X或Y轴对称的生成一些抓取点,从而将前面朝上的抓取点变成多个朝向的抓取点,再通过抓取点排序节点设置抓取策略进行排序,虑除掉朝上的抓取点。而绘制抓取点节点可将抓取结果绘制出来以便调试查看结果。
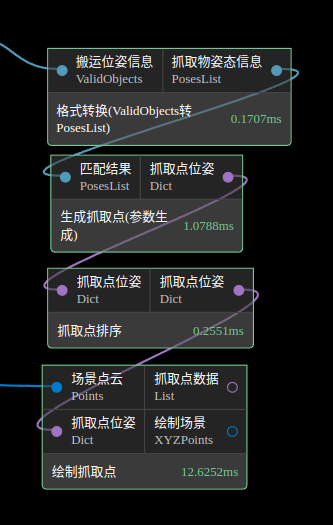
注意: 在对搬运位姿的处理节点中,除了生成搬运位姿节点需要输入相机坐标系下点云外,其他节点均需输入点云需为机器人坐标系下点云 |
参数调优
(1) RoI选取的参数调优
配置3维RoI 和 配置2维RoI 算子,都可以在ATOM中的运行时参数,进行可视化编辑。
若该图要与EpicPro进行联调,则可通过EpicPro输入节点输入3维ROI进行后续处理。
(2) 模型参数调优
以下深度学习相关节点的模型基本都可以通过训练服务获取
以下节点的返回值均为DetectInstance的结构,是包含dict的列表:
-
"score": 检测结果置信度
-
"class_name":检测结果类别
-
"polygon": 检测结果Mask
-
"angle": 检测结果的角度,只有带旋转的箱子检测和2D形状匹配节点有这个结果,一般为0
1. 袋子分割
-
GPU运行时间约340ms,CPU运行时间约2200ms(测试环境为1650显卡,8核32G)
-
置信阈值:取值范围为[0,1],当结果数量较少时,可以将该值下调
2. Caffe2袋子分割
-
模型可用pth模型在训练服务测试与导出页面中转换得到,或在查看模型页面已有导出模型中下载,得到的是.zip的压缩包,里面包含的是其中导出时选择了GPU则导出的是GPU模型,会以_cuda.zip结尾去命名压缩包,若导出时未选择GPU则导出的是CPU模型,会以_cpu.zip去命名压缩包。在节点中用的是哪个模型,就会对应去使用CPU或GPU运行。
-
GPU运行时间约240ms,CPU运行时间约1000ms(测试环境为1650显卡,8核32G)
-
模型文件:模型文件,存储的模型中各个层训练好的数据,从训练服务中下载的zip包进行解压后的model.pb文件
-
模型参数文件:模型参数文件,存储的是模型的结构,从训练服务中下载的zip包进行解压后的model_init.pb文件
-
置信阈值:取值范围为[0,1],当结果数量较少时,可以将该值下调
3. 箱子检测
-
GPU运行时间约80ms,CPU运行时间约5500ms(测试环境为1650显卡,8核32G)
-
置信阈值:取值范围为[0,1],当结果数量较少时,可以将该值下调
-
是否旋转:当物体会出现不定的旋转角度时打开,注意对应模型的选择
旧版标注模型:这一参数只在旋转检测的时候生效,是为了将之前旋转检测标注规则训练的模型与现有旋转矩形标注规则区分开,用于结果绘制,若设置错误可能会导致模型识别对了,但结果显示错误。
4. 箱子检测Onnx
-
模型可用pth模型在训练服务测试与导出页面中转换得到,或在查看模型页面已有导出模型中下载
-
GPU运行时间约70ms,CPU运行时间约3800ms(测试环境为1650显卡,8核32G)
-
置信阈值:取值范围为[0,1],当结果数量较少时,可以将该值下调
-
是否旋转:当物体会出现不定的旋转角度时打开,注意对应模型的选择
旧版标注模型:这一参数只在旋转检测的时候生效,是为了将之前旋转检测标注规则训练的模型与现有旋转矩形标注规则区分开,用于结果绘制,若设置错误可能会导致模型识别对了,但结果显示错误。
gpu运行时间约65ms
5. YOLO分割
-
GPU运行时间约160ms,CPU运行时间约1000ms(测试环境为1650显卡,8核32G)
-
置信阈值:取值范围为[0,1],当结果数量较少时,可以将该值下调
6. YOLO检测
-
GPU运行时间约70ms-180ms,CPU运行时间约150ms~600ms(测试环境为1650显卡,8核32G),这个与训练时的预训练模型有差别
-
置信阈值:取值范围为[0,1],当结果数量较少时,可以将该值下调
7. 形状模版匹配
-
强制训练:若强制训练,则每次初始化都会训练一次模板,否则若已存在模板则不会训练模板图
-
模板图片:根据待匹配场景,可用生成模板图片节点输入相机内参和目标高度范围来生成一个图片下载后上传到此处,同时,该节点输出的缩放范围可以作为缩放范围参数
-
模板生成路径:可默认也可以指定,若指定则会在指定路径下生成两个.yaml文件,默认则是在当前atom图路径下生成该文件
-
模板名字:可用默认值,也可指定,指定是为了多模板情况进行设置
-
是否缩放:缩放是对图像和模板进行缩放,以减少训练时间,但可能会造成精度不够的情况
-
缩放比例:取值范围为[0,正无穷],为缩放定值,会对输入图像进行固定比例的缩放
-
缩放范围:是一个数组,长度为2,表示一个缩放区间,比如 [0.8, 1.2]
-
缩放步长:取值范围为[0,区间长度],在缩放范围内逐步进行搜索,越小越精细,同时也更加耗时
-
旋转角度范围:是一个数组,长度为2,表示一个旋转范围区间,比如 [0, 360],单位是度
-
旋转角度步长:取值范围是 [0,区间长度],在角度区间内逐步进行搜索,越小越精细,同时更加耗时
-
特征点数量:是一个整数,取值范围是 [1,正无穷],数量越多匹配越精确,但也更加耗时
-
图像金字塔层级:是一个数组,每一个元素表示图像金字塔的比例,为2的幂次,越小匹配像素精度越高,也越费时
-
得分阈值:得到的结果分数阈值,越大则留下的结果越多
-
NMS阈值:会根据此值过滤掉重叠过大的结果
-
类别名:根据场景设定类别名称,用于后续过滤操作
(3) 结果过滤参数调优
1. RoI过滤
-
无参数,直接使用3维的RoI对搬运位姿进行过滤
2. 面积过滤
-
原理:
-
过滤出满足\(\frac{|S - S^{'}|}{S}\ \leq \ \varepsilon \)的物体, 其中\(S\)是目标物体的面积,\(S^{'}\)是检测到的物体的面积,
-
-
参数:
-
面积:取值范围为[0,正无穷],设定2维的面积,单位为平方毫米,也就是上式中的\(S\)
-
过滤阈值:取值范围为[0,正无穷],越小越严格,也就是上式的\(\varepsilon\)
-
-
调参技巧:
-
可以通过搬运位姿数据中最接近真实值的结果中"object_info"的area字段去得到面积,这里的单位也是mm,如"object_info": \{ "area": 421849.2505262555},但这一方法需要得到的目标polygon跟实际目标基本对应。
-
对于类似矩形的目标,可用cloudcompare在点击点去测量长宽,用长*宽来得到面积。
-
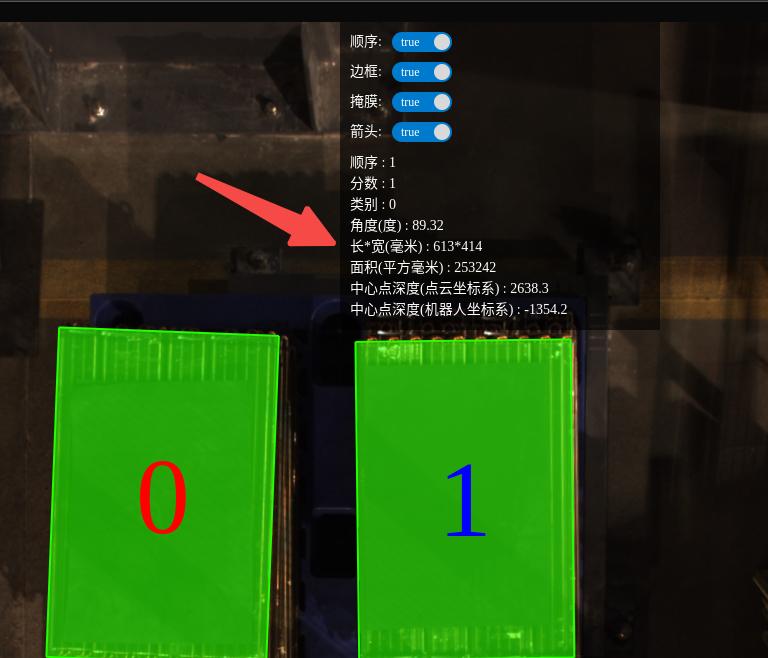
可在上一个节点的输出ImageShowInfo绘制的图像放大后把鼠标放到可抓取的目标上,上面显示的面积值可作为此处的面积参数。
-

-
当面对目标大小有差异时,若要将这些目标都保留,可使用要保留的结果中,结果mask较大的面积和结果mask较小的面积的中间值去做过滤。
3. 尺寸过滤
-
原理:
-
过滤出满足\(\max\ \Big\{ \frac{|w - w'|}{w},\ \frac{|h - h'|}{h}\ \Big\} \leq \varepsilon \)的物体,其中\(w,h\)是目标物体的宽高,\(w^{'},h^{'}\)是检测到物体的宽高
-
-
参数:
-
长边:取值范围为[0,正无穷],即上式中的 \(h\)
-
短边:取值范围为[0,正无穷],即上式中的 \(w\)
-
阈值:取值范围为[0,正无穷],越小越严格,即上式的\(\varepsilon\),当过滤后结果数量较少时,可以往大了调整
-
-
调参技巧:
-
当前若难以现场测量目标物体的长宽时,可用cloudcompare在点击点去测量长宽,也可以通过搬运位姿数据中最接近真实值的结果中"object_info"的size字段去得到长宽,这里的单位也是mm,如"object_info": \{"size": [1289.0364607399779, 638.5852627871186]},但这一方法需要得到的目标polygon的最小包围矩形跟实际目标基本对应。
-
可在上一个节点的输出ImageShowInfo绘制的图像放大后把鼠标放到可抓取的目标上,上面显示的长宽的值可作为此处的长边短边参数
-
-
当面对目标大小有差异时,若要将这些目标都保留,可使用要保留的结果中,结果mask较大的尺寸和结果mask较小的尺寸的中间值去做过滤。
4. 重叠过滤(基于边缘重叠)
-
原理:
-
根据检测结果的掩膜对应的深度图,执行边缘重叠判断
-
输入点云需为机器人坐标系下点云
-
-
参数:
-
边缘膨胀大小:取值范围为[0,正无穷],对所有掩膜图像进行膨胀,此值代表做膨胀的核的大小,该值越大则边缘的宽度会膨胀得越宽
-
重叠区域深度差:取值范围为[0,正无穷],是重叠处边缘的平均深度差值的阈值,深度差值大于此值则认为出现重叠, 阈值设置越小,过滤越严格,过滤掉的目标越多
-
机器人坐标系z轴朝向:取值可能为[上,下],用于调整抓取的方向
-
-
调参技巧:
-
此节点并无经验参数,在运行时,前后端会输出中间结果,可以先设置膨胀区域,重叠区域深度差调小,然后运行该节点,查看输出的不同目标之间的重叠区域深度差值,参考这些值去调整参数。
-
同时,输出的结果中,若有重叠关系,也会用箭头绘制,箭头起点的目标重叠在箭头终点的目标上,箭头上方的值表示两个目标包围框之间的重叠边缘处的深度差值,与参数重叠区域深度差进行比较判断。
-
5. 重叠过滤(基于包围框交叉)
-
原理:
-
根据检测结果的掩膜对应的深度图,执行NMS或边缘重叠判断,边缘重叠判断主要针对最小包围框有交叉且掩膜出现缺角的情况
-
输入点云需为机器人坐标系下点云
-
-
参数:
-
最小包围框IoU阈值:取值范围为[0, 1],该值越小过滤的越严格。如果两个掩膜的IoU大于此值,才继续做进一步的掩膜重叠判断,小于此值则认为不重叠,不进行下一步判断。
-
只判断IOU:若此值打开,则只判断IOU大小进行过滤,即做一次NMS,否则会先判断IOU再判断两个目标间mask重叠比例
-
重叠比例差阈值:
-
\(\Big\vert\ \frac{ B\_ i\cap\ B\_ j\ \cap\ S\_ i}{ S\_ j} - \frac{ B\_ i\cap\ B\_ j\ \cap\ S\_ j}{ S\_ i}\Big\vert\ \leq\ \varepsilon \) 其中 \(B_{i},\ B_{j}\) 是包围框的区域,\(S_{i},\ S_{j}\) 是掩膜的区域
-
两个掩膜在包围框重叠区域占比的差,大于此值的两个掩膜才认为两个目标有重叠,并据此判断出哪一个被重叠, 值越小,过滤越严格, 过滤掉的相对多
-
-
调参技巧:
-
此节点并无经验参数,在运行时,前后端会输出中间结果,可以先将重叠比例调小,然后运行该节点,查看输出的不同目标之间的重叠比例和IOU,参考这些值去调整参数。
-
同时,输出的结果中,若有重叠关系,也会用箭头绘制,箭头起点的目标重叠在箭头终点的目标上,箭头上方的值中,上面那个值表示两个目标间的重叠度,与参数重叠阈值进行比较判断,下面那个值表示两个目标包围框之间的IOU,与参数IOU阈值进行比较判断。
-
6. 最高层过滤(基于最高层高度)
-
原理:
-
对检测结果执行最高层过滤, 根据最高层物体高度的一半过滤掉其他物体。
-
输入点云需为机器人坐标系下点云
-
-
参数:
-
物体实际厚度:单位为毫米,取值范围是 [0, 正无穷],越接近真实物体的厚度越好
-
7. 最高层过滤(基于上层点)
-
原理:
-
多用于判断各检测结果是否被遮挡可抓取,避免错层抓取。此方法是为了过滤掉上层未能识别到,识别到下层被压叠的目标的情况。
-
ROI内上层点方法是: 判断ROI内目标周围上层点的数量,大于阈值则认为被遮挡,过滤掉,否则保留;
-
目标周围上层点方法是:对每个目标位姿,对mask的最小包围框外扩一定范围(最小包围框短边的一半长度),
-
计算这个范围内比目标抓取点高一定范围(半个实物高度)的像素面积与该目标mask像素面积的比例,
-
若大于阈值则目标会被过滤掉,否则保留。此方法适用于摆放较规整,目标z向厚度较大的场景
-
-
参数:
-
上层点判断区域:可选的方法,有 1. ROI内上层点; 2. 目标周围上层点
-
物体实际厚度:单位为毫米,取值范围是 [0, 正无穷],越接近真实物体的厚度越好
-
ROI内上层点 上层点数阈值:ROI内计算出来的目标上层深度值数量大于此值,则该目标被过滤,此值越小,过滤掉的结果越多。
-
目标周围上层点 过滤阈值:计算出来的目标周围上层点数量与目标对应点数量比例大于此值, 则该目标被过滤, 此值越小,过滤掉的结果越多。一般在箱子等形变量较小的场景下,此方法可选用。
-
-
调参技巧:
-
针对此节点,输入应该是经过ROI以后的机器人坐标系下的点云,且需选用nan值填充。
-
此节点并无经验参数,在运行时,前后端会输出中间结果,可以先设置实际的厚度,然后当使用ROI内上层点时,先将上层点数阈值调小,运行该节点,再查看输出中用于比较的结果点数,参考这些值进行参数设置;当使用目标周围上层点时,先将过滤阈值调小,运行该节点,查看输出的各目目标用于比较的结果点数,参考这些值去调整参数。
-
8. 类别过滤
-
原理:
-
通过输入的搬运位姿中的类别判断是否等于需要类别,过滤掉多余类别
-
-
参数:
-
保留类别:要保留的类别,默认0类
-
是否使用替补类别:若为True,则在0类为空时使用替补类别,否则不使用题目类别,输出只包含要保留类别或为空
-
替补类别:当要保留的类别没有检测到时,使用其他类别进行处理
-
(4) 结果生成参数调优
1. 生成搬运位姿
-
原理:
-
对深度学习方法的检测结果进行重新整理,加入点云和手眼标定相关信息, 使其转换为方便处理和传递的形式。
-
输入点云为相机坐标系下点云
-
-
参数:
-
圆半径: 圆半径比例, 相对于包围框短边一半的比例, 用于选取物体表面点云以计算深度,这里得到的深度会用来计算抓取点的z值
-
抓取点z值计算方法:抓取点z值一般用均值计算,但针对场景下点云飞点很多的情况,用中位数去计算有可能避免飞点造成的抓取点不准的情况
-
使用检测结果角度:若打开,则使用检测结果中角度计算结果位姿旋转,若关闭则使用检测结果最小包围框长边对应机器人坐标系点云与坐标系轴的角度关系来做Rz的旋转
-
返回值:
-
ValidObjects的数据结构,是包含dict的列表:
-
"uuid": 唯一标识符,在最后生成EpicPro结果的时候会使用到
-
"score": 2d检测、分割、匹配得分
-
"class_name": 类别名称(integer类型)
-
"polygon": 结果mask
-
"min_area_rect": 结果mask的最小包围框
-
"mean_depth": 相机坐标系下结果mask对应区域点云的深度值
-
"area": 结果mask的2d面积
-
"angle": 检测结果的角度,来源于DetectInstance,只有带旋转的箱子检测和2D形状匹配节点有这个结果,一般为0,这个角度在使用检测结果角度为True时会被用到
-
"center_point": 相机坐标系下结果mask区域的中心点
-
"pose": 机器人坐标系下的可抓取位姿
-
"normal": 法向,默认为[0,0,1],只有在搬运位姿估计节点处会被修改
-
"object_info": object_info = \{“size”: , area“”},这里包含的是结果目标对应到点云坐标系下的最小包围框长宽和面积,可跟实际尺寸和面积对应
-
-
-
2. 搬运位姿估计(基于点云包围框)
-
原理:
-
使用聚类方法对点云进行聚类,选取数量最多的类,根据该类的点云使用PCA进行法向量估计
-
输入点云需为机器人坐标系下点云
-
-
参数:
-
聚类方法:有 dbscan 和 optics_segmentation
-
dbscan 搜索半径:取值为[0, 正无穷] dbscan聚类中,每一个种子点的搜索半径,越大则聚类越少
-
dbscan 密度条件:取值为[0, 正无穷],每一个种子点的搜索半径内最少需要有的点云点数,即为密度条件,越大则聚类越严格聚类数越少,越小则聚类越宽松聚类数越多
-
optics_seg 截断阈值:取值为[0, 正无穷],越大则聚类数越少,但是如果过小可能导致没有聚类结果
-
optics_seg 搜索点数:取值为[0, 正无穷],每一个种子点的k近邻搜索点数,越小则聚类数越多,越大则聚类数越少
-
聚类最少点数:每一个聚类簇中最少包含的点云点数
-
聚类最多点数:每一个聚类簇中最多包含的点云点数
-
3. 搬运位姿估计(基于点云法向)
-
原理:
-
计算抓取法向量, 即根据物体表面点云, 算出抓取点处的法向量, 给出最终沿法向抓取的位姿。
-
输入点云需为机器人坐标系下点云
-
-
参数:
-
圆半径:取值为[0, 正无穷],为圆半径比例, 相对于包围框短边。参数值越大,参与法向估计的点云点越多,计算越慢,所以根据不同目标尺寸需要设置不同阈值
-
法向量计算方法:可选的有 CC 和 PCL
-
PCL 视点:默认为[0, 0, 0],采用PCL的法向估计算法时, 需要设置视点, 代表法线计算方向
-
CC 算法模型:采用CC的法向估计方法时需要设置局部结构计算模型,可选的有"局部最近", "三角片", "四边形片"
-
CC 法线方向:可选的有 "正X", "负X", "正Y", "负Y", "正Z", "负Z", "背离重心", "指向重心", "背离原点", "指向原点"。采用CC的法向估计方法时需要设置法线方向, 默认为负Z方向
-
4. 搬运位姿排序
-
原理:
-
根据参数中选择的不同排序方法进行结果的排序
-
-
参数:
-
排序方法:可选高度、分数、面积,可根据前面计算出来的validObjects中的机器人坐标系下高度(x["pose"][2])、2D检测得分(x["score"])、检测polygon面积(x["area"])进行排序,以保证抓取为从上到下。
-
机器人坐标系朝向:根据实际机器人坐标系z轴朝上还是朝下进行设置。
-
5. 格式转换(ValidObjects转PosesList)
-
原理:
-
将搬运位姿转换为抓取物位姿,保留其中的得分和位姿
-
6. 搬运位姿排序(同层)
-
原理:
-
根据参数对过滤后的同层目标进行左右和上下的排序,并可选合并与S型抓取
-
-
参数:
-
排序坐标系:可选像素坐标系(默认)和机器人坐标系
-
距离阈值:
-
认为两个抓取物之间x或y的实际距离小于这个阈值的两个抓取物在同一行或者同一列。
-
若坐标系选像素坐标系(默认),则会在像素坐标系下进行排序,对应的距离阈值也应该按像素上的距离进行设置,会将此值转换到像素坐标系去计算,若获取到的输入intrinsic为None或者validobjects的平均mean_depth为nan时, 将此值作为两个物体之间的像素距离阈值去排序;若坐标系选择机器人坐标系,则会在机器人坐标系下用validObjects中的pose[:2]进行排序,距离阈值需要用实际的目标中心之间的距离进行设置。
-
-
横纵向抓取物抓取顺序:
-
可选值为:'不区分横纵抓取物', '先横向抓取物', '先纵向抓取物'
-
节点中将目标按照目标的2d检测结果最小包围矩形的角度的cosine值与cos(70)和cos(20)的大小关系,分为横向抓取物和纵向抓取物,横向是指目标长边在x轴方向的结果,纵向是指目标长边在y轴方向的结果。
-
设置的不区分横纵抓取物,是将所有目标一起按照目标抓取规则进行排序,若区分横纵向抓取物,则将横纵向抓取物分成两部分分别按照对应的横向抓取物排序规则和纵向抓取物排序规则进行排序,并分为先抓横向抓取物还是先抓纵向抓取物。
-
-
目标排序规则、横向抓取物排序规则、纵向抓取物排序规则:
-
***可选值均为:'从左往右从上到下', '从左往右从下到上', '从右往左从上到下', '从右往左从下到上', '从上到下从左往右', '从上到下从右往左', '从下到上从左往右', '从下到上从右往左',具体的抓取顺序见下图
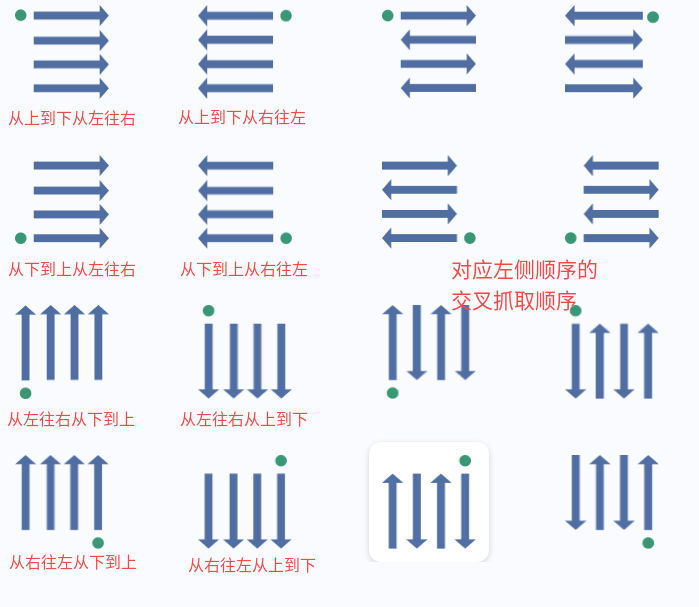
抓取规则可以认为有两层,表示为第一层抓取顺序+第二层抓取顺序,第一层为整体的抓取顺序,第二层为按整体顺序排序后每一行或每一列的排序顺序。
从左往右从上到下规则代表:整体按照从左往右一列一列进行抓取,每一列中按照从上到下进行抓取;
从上到下从左往右规则代表:整体按照从上到下一行一行进行抓取,每一行中按照从左往右进行抓取;
同理,其他几种规则是类似的。
当不区分横纵抓取物时,则按照设置的目标排序规则进行排序,若区分横纵抓取物,则将横向抓取物按横向抓取物排序规则排序,纵向抓取物按纵向排序规则进行排序。
-
是否交叉抓取:
-
是否S型交叉抓取, 默认不交叉抓取, 只在不合并时生效
-
交叉抓取的意思是,若排序规则设为从上到下从左往右,则按第一行从左往右,第二行从右往左,第三行从左往右,第四行从又往左,以此类推;若排序规则设为从左往右从上到下,则第一列从上到下,第二列从下到上,第三列从上到下,以此类推;其他排序规则同理。
-
由于ATOM实际限制,无法记录上次的抓取顺序,此规则可以认为只能用在拍一次抓一层的的场景下。
-
-
是否合并:
-
合并是指按照设置的抓取规则进行排序,然后对抓取规则的第二层进行合并。如:
-
从左往右从上到下规则在合并时会从左往右一列一列合并进行抓取,从上到下从左往右规则在合并时会一行一行从上到下进行抓取。
-
-
目标合并个数:
-
合并个数只是否合并参数为True时有效,且值为一个list,默认为[-1, -1]
-
参数中的每个值代表着合并时几个目标为一组进行合并,此值需要为-1或为>0且<当前要合并行或列的目标总数,值为-1时,将当前行或者列整体合并。
-
当不区分横纵抓取物时,按照参数的第一个值进行合并;当先横向抓取物时,横向抓取物按照第一个值进行合并,纵向抓取物按第二个值进行合并;当先纵向抓取物时,纵向抓取物按第一个值进行合并,横向抓取物按第二个值进行合并。
-
可实现结果示例:
参数: 不区分横纵向抓取物,从左到右从上到下,[-1,-1],合并
|
参数: 先横向抓取物,横向抓取物规则:从上到下从左往右,纵向抓取物规则:从右到左从下到上,不合并,不交叉
|
参数: 先纵向抓取物,横向抓取物规则:从下到上从左往右,纵向抓取物规则:从右到左从上到下,不合并,不交叉
|



7. 生成抓取点(参数生成)
-
原理:
-
通过设置X、Y、Z轴的平移和沿X、Y、Z轴对称离散的数量来得到一系列对称的抓取点
-
-
参数:
-
叠加X轴平移:抓取点的x值偏移对应值(+或-)
-
叠加Y轴平移:抓取点的y值偏移对应值(+或-)
-
叠加Z轴平移:抓取点的z值偏移对应值(+或-)
-
沿X轴对称(角度离散数目):若设为a,则会将360度等分为a份,得到一个角度360/a,将抓取点绕X轴旋转,每360/a度生成一个抓取点。
-
沿Y轴对称(角度离散数目):若设为b,则会将360度等分为a份,得到一个角度360/a,将抓取点绕Ys轴旋转,每360/a度生成一个抓取点。
-
沿Z轴对称(角度离散数目):若设为c,则会将360度等分为a份,得到一个角度360/a,将抓取点绕Z轴旋转,每360/a度生成一个抓取点。
-
若对称的参数不全为0,则先旋转,再按照抓取点的坐标轴平移对应的值,最后生成的抓取点个数为a+b+c个
如下左图结果对应的参数为右图中,Y轴平移-90,沿X轴对称离散10个:
|
|

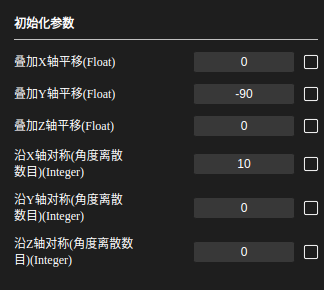
在本流程中,大部分只需要设置沿X轴或Y轴对称离散2个抓取点,然后根据实际抓取设置Z轴平移即可
8. 抓取点排序
-
原理:
-
通过添加不同的排序策略对生成的抓取点进行排序
-
-
参数:
-
抓取点个数:针对每一个结果,保留几个抓取点,可保留多个,然后到EpicPro中进行碰撞检测和路径规划
-
抓取点生成策略:
-
多种策略通用参数:
-
排序顺序:可设置为"HIGHEST"或"LOWEST". 指定对计算得到的距离的排序顺序, 设置为"HIGHEST"为距离较大的抓取位姿排序靠前, 设置为"LOWEST"相反.
-
差异阈值: 指定该项排序生效的阈值
-
分组阈值:排序分组间隔
BY_POSITION_ALONG_TARGET_FRAME_AXIS:
-
按照抓取点在Target Frame下的某个坐标轴的分量大小进行排序,常可用于按Z轴高度进行排序
-
参考系坐标轴(String):被抓取物坐标轴, 指定物体坐标系的某一轴, 可设置为"X_AXIS", "Y_AXIS"和"Z_AXIS"。
-
排序顺序(String): [HEIGHTST, LOWEST]
-
差异阈值(Float): 如果计算得到两个抓取位姿间沿指定axis_of_target_frame距离小于该阈值,则认为两抓取点在此排序规则下优先级相同.
-
分组阈值(Float):排序分组间隔
BY_ANGLE_TO_AXIS:
-
按照抓取点的某个坐标轴(X or Y or Z)在Target Frame下的指定轴的夹角大小进行排序
-
抓取点坐标轴(String): 指定抓取点坐标系的某一轴, 可设置为"X_AXIS", "Y_AXIS"和"Z_AXIS".
-
目标轴(List): 指定空间中某一向量作为目标轴计算旋转角度,常设为[0,0,-1]
-
排序顺序(String): [HEIGHTST, LOWEST]
-
差异阈值(Float):
-
角度阈值(Float): 夹角阈值, 抓取点计算得到夹角大于(小于)该阈值时, 不使用该抓取点.
-
分组阈值(Float):
BY_ANGLE_TO_POINT:
-
按照抓取点的某个坐标轴(X or Y or Z)与 指向抓取点的射线(由Target Frame下一个给定的viewPoint确定)的夹角大小进行排序,即抓取位姿某一轴与抓取点和所设置参考点之间连线的夹角排序
-
抓取点坐标轴(String): 指定抓取点坐标系的某一轴, 可设置为"X_AXIS", "Y_AXIS"和"Z_AXIS".
-
参考点(List): 一般设置为料框上方机械臂末端起始规划点.
-
排序顺序(String): [HEIGHTST, LOWEST]
-
差异阈值(Float):
-
角度阈值(Float): 夹角阈值, 抓取点计算得到夹角大于(小于)该阈值时, 不使用该抓取点.
-
分组阈值(Float):
BY_DISTANCE_TO_POINT:
-
按照抓取点与Target Frame下给定点的距离进行排序
-
指定参考点位置(List): 该参考点为抓取点坐标系下x,y,z值.
-
排序顺序(String): [HEIGHTST, LOWEST]
-
差异阈值(Float):抓取点计算得到距离大于(小于)该阈值时, 不使用该抓取点.
-
角度阈值(Float): 夹角阈值, 抓取点计算得到夹角大于(小于)该阈值时, 不使用该抓取点.
-
分组阈值(Float):
BY_SCORE:
-
按照score进行排序
-
排序顺序(String)
-
差异阈值(Float)
-
得分阈值(Float):得分大于(小于)该阈值时, 不使用该抓取点.
-
分组阈值(Float)
BY_PRIORITY:
-
按照priority进行排序,priority数值越小,优先级越高,顺序越靠前,抓取点priority可从EpicPro进行设置
-
排序顺序(String)
-
优先级差异阈值(Float):优先级差异大于(小于)该阈值时, 不使用该抓取点.
-
优先级阈值(Float)
-
分组阈值(Float)
BY_DISTANCE_TO_BIN_SIDES:
-
按照抓取与料框壁之间的距离关系进行排序,该策略仅适用于料框无序抓取, 根据抓取点到料框边缘的距离排序.
-
排序顺序(String)
-
料框中心点位置(List):矩形料框的位姿矩阵, 原点位于料框的几何中心, 位姿矩阵的x轴和y轴与料框的两边平行
-
X方向比较阈值(Float):料框模型X方向一半长度.
-
Y方向比较阈值(Float):料框模型Y方向一半长度.
-
差异阈值(Float)
-
分组阈值(Float)
BY_ANGLE_TO_BIN_SIDES:
-
按照抓手到达抓取点时正方向与料框壁法向量之间的关系进行排序,当料框为矩形时, 建议使用该策略,根据抓取位姿某一轴与最近的料框壁法向量夹角排序
-
排序顺序(String)
-
抓取点坐标轴(String):抓取点坐标轴, 指定抓取点坐标系的某一轴, 可设置为"X_AXIS", "Y_AXIS"和"Z_AXIS"
-
料框中心点位置(List): 料框中心点在抓取点所在坐标系下位姿, 抓取点所在坐标系一般为机器人基坐标系.
-
料框X方向一半长度(Float): 料框模型X方向一半长度.
-
料框Y方向一半长度(Float):料框模型Y方向一半长度.
-
X方向比较阈值(Float): 料框模型X方向阈值,在该阈值内的抓取点优先级相同,不进行比较.
-
Y方向比较阈值(Float):料框模型Y方向阈值,在该阈值内的抓取点优先级相同,不进行比较.
-
差异阈值(Float)
-
分组阈值(Float)
BY_ORIENTATION_DIFFERENCE_OF_TOOL_TO_PICK_POINT:
-
按照抓取点位姿与规划开始点位姿之间的差异进行排序(位置差异,姿态差异),该策略仅适用于料框无序抓取, 首先根据料框尺寸(boundary_in_x_dir, boundary_in_y_dir)过滤料框边缘的抓取点,优先抓取料框中心的抓取点,然后工具末端初始位姿与抓取点位姿的姿态差异(角度)进行排序
-
排序顺序(String)
-
工具初始位置(List):工具末端初始位姿, 一般为规划的初始位姿.
-
差异阈值(Float)
-
分组阈值(Float)
抓取策略常用的还是前面几种
9. 绘制抓取点
-
主要是用于调试阶段查看实际抓取点结果,输入为场景点云和抓取点位姿。
-
针对本流程可通过绘制抓取点节点在使用搬运位姿估计节点后查看抓取的法向朝向是否计算准确,也可以在生成搬运位姿节点参数使用检测结果角度设置为false时,查看抓取点的x轴或y轴与目标长边是否平行。